C code. C code run. Run code run...please!
-- Barbara Ling
Introduction
In one of the murky corners of C++ we find all the rules for static initialization hidden. They hide here because they are hideous, deformed and frightening. If they were out in the open, noone in their right mind would start down the path of actually learning and using C++. Or so I would think. Anyways, if you're with me in the boat of "we're already screwed and we have to use C++" then read on and we'll try to put some pretty clothes on the monsters instead.
This article is in part inspired by numerous discussions online and with colleagues. There is a lot of confusion and the subject matter is not really that trivial to begin with.
Sections of your executable
Looking at your executable in a binary dumper, you will notice that there are several sections. Most of these can be examined through an object file dumper, the one for the GNU bintools is simply called objdump. For Microsoft compiler users, the tool is called dumpbin.exe. Using this tool you can inspect the output from the compiler and also the output from the linker. We're going to look at a limited number of sections, you can define your own, from the compiler. These are called .text, .data and .bss.
What the heck do they stand for?
So where do my variables wind up? It depends. If you have simple data assigned to your variables they usually wind up in the .data segment with their values already there. If they on the other had are unassigned, then they do not really need to exists on disc, but can be inferred at runtime. Thus they wind up in the .bss section. The .bss section also niftily gets initialized to zero. Note that this is something that the executable loader does for you, it has nothing to do with the language itself!
float pi = 3.14f; // in .data int counter; // in .bss, initial value will be 0.
On a historical note, the name BSS is actually an acronym for Block Started by Symbol, a pseudo-op in an old fortran assembler. It was picked up by C and Unix in the old days and has thus stayed on.
The .bss section is really the only tricky one, the .text and .data segments are just memory mapped in from the executable. The .data (or .rodata) segment is simply all your constant initialized data and the .text segment is your code. Depending upon your runtime there can be need for relocation code to be executed as well.
Static and dynamic initialization
All of your objects that are declared in the file scope are the most common objects with static storage duration, there are others, but for simplicity's sake let's forget about them for a while. Objects with static storage duration are required by the language to be first zero/constant initialized before anything else happens. This is called the static initialization. After that the really tricky part comes, the dynamic initialization. This is the phase where the constructors and other function calls are made. The order between translation units are undefined, or up to the compiler's digression. In a single translation unit, the initialization goes in the order they were declared. More on this...
Order of initialization
One of the things that can trip you up is that there is no specific order of initialization in the static constructors. Not really in practice, as we discussed before there is some rules, but for the most part they are useless. For example, if we look at the following code:
CreatorMap g_creators;
void WidgetFactory::addCreator( const char* name, Widget* (*creator)() )
{
g_creators.insert( CreatorMap::value_type(name, creator) );
}
It looks perfectly reasonable. The problem is that the constructor for the std::map is not guaranteed to be run before any call to addCreator. Given that the g_creators variable will be placed in the .bss section, all it's member will hold zero, which in the end causes a very mysterious crash upon startup. Worst is that it is not obvious what went wrong looking at the code.
What about the Meyer's singleton?
In the many uses of the static keyword, function scope static variables are required and guaranteed to not run before the enclosing function is called, but will obviously run when then function is called. This gives us a way out as we can wrap our global variables in what has become known as a Meyer's singleton:
Foo& instance()
{
static Foo& theInstance;
return theInstance;
}
The code above will usually be translated to something similar to:
Foo& instance()
{
static bool isInitialized = false;
static char theInstance[sizeof(Foo)];
if( !isInitialized )
{
new (theInstance) Foo;
add_at_exit_handler( destructorForFoo, theInstance );
}
return *((Foo*)(theInstance));
}
This allows us to cascade dependencies whenever we call functions from a static constructor somewhere. If anything has dependencies on any other system, we can encode them in the singletons. This is particularly useful for systems like memory trackers and log systems.
A word of caution though, singletons are really just global variables with a fancier name. They are still global variables though. And they're really really bad if they explode in numbers and dependencies. They're particularly nasty if they're not thread safe and you are trying to write thread safe code. If all possible, try to avoid using too many singletons.
Strange compiler exceptions
So after all these scary stories the really informed reader notices that for example UnitTest++ relies heavily on automatic registration through static constructors. WTF? It's not all so bad as that, it actually works for UT++. The reason is that for some strange reason most compilers and linkers decide to run all the static constructors in the main executable project (or the object files explicitly called out on the link line) before main() all the time (ok, only tested on gcc and msvc but that kind of covers most use cases).
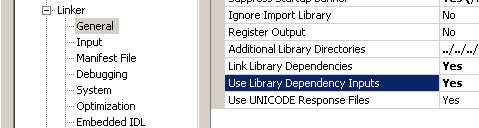
An extension of this rule is that if you actually call out all our object files individually on the link-line, it should in most cases just work. Nothing says though that it will continue to work, this is just observed behavior for the current generation of compilers so I would advice against it. But it you really really want it and are willing to take a little bit of uncertainty, then if you're lucky enough to be on the visual studio compiler, you can enable the option "Use Library Dependency Inputs". This is originally introduced as a means to speed up incremental linking, but it has this somewhat odd (although not totally unexpected) side effect. Of course this will break as soon as someone decides to change that linker setting.
Alternatives
Although the nifty magic behind the scenes is so alluring, the harsh reality is that it's often more problems than it's worth. Combined with the fact that it really messes with your head to debug these things, maybe we should explore alternatives? The simplest that comes to mind is to just explicitly call out all the Widgets that we want the factory to know about and require that people register them, or alternatively provide a library function for initialization of the Widget library.
This explicit initialization is vastly more simple and we can follow it in the debugger pretty easily. The downside is that we will have a choke point of sorts where all the known types need to be included and called out one by one, usually manually and this can be a source of error if you need to have this list synchronized.
In closing
Static initialization is something that looks very convenient but it's really a little tricky in the end. A lot of the criticism of C++ of doing things behind the programmers back applies for static initialization. When and where is entirely controlled by the compiler and the linker, the programmer have little control over the process. Usually the solution is to be a little bit more explicit and call out the functions you want to call yourself at the expense of a little flexibility.
Feel free to download and play around with the little project attached at the bottom. It's a standard visual studio solution, with one library and a main console program. Messing around with the settings and recompiling shows some fun stuff, like reference optimizations doesn't really matter in terms of what gets run before main. It's also a small example of the how to create project files for BadgerConfig.
Resources
- Widget test program. Full source and project files.
References
- http://www.faqs.org/faqs/unix-faq/faq/part1/section-3.html
- http://msdn2.microsoft.com/en-us/library/ms809762.aspx