To err is human, but to really foul things up you need a computer.
-- Paul Ehrlich
Introduction

So what's wrong with the "traditional" way of having a group of developers write code, checkin and get latest in isolation? It's been working for several projects, right? So why should we fix something that isn't broken?
Well, I could argue that it is broken. I obviously don't know what kind of problems you have at your company, but I know that in the past I've been faced with broken builds and didn't even know that it was a problem until much much later.
In projects with multiple of executables that all need to be built in a multitude of configurations it can quickly overwhelm the developer to just build everything each time you change something. Something like <Core/New.h> ... Or some innocuous change somewhere that clearly isn't used anywhere else so I'll just check it in... Sounds familiar? Clearly building everything on the client machine before checking in is impractical, since it would take considerable amount of time just to build everything each time. Long checkin procedures usually leads to developers taking shortcuts and working on several things at once and then taking the hit of checking in later on, which in turn leads to larger change lists which in turn leads to harder to track changes and in the end horrible horrible bugs.
But checkins in the dark are usually breaking ones. Not in the main project. But in some obscure tool. Which of course you some weeks later on need to make a change in. Only not only doesn't it compile, but now it's riddled with bugs accumulated from several change lists over the course of six months. Sorting it out takes you the rest of the week.
Continuous integration
Continuous integration is the practice to have a server machine do a build of the repository after each commit. It's as easy as that. Almost. It's really easy to setup a server to do automatic builds, I'll describe one process later on in this article. The hard part comes from spreading a culture that a broken build is a bad bad thing. And getting people to fix it automatically. It is very easy to slip into the habit of ignoring these messages and let someone else deal with it.

At one point I was stupid enough to setup a very very naive build server on a team I was on. We had builds on three platforms (Win32, Tools and Xbox) with a multitude of projects that needed checking. At the time we had problems that once you was forced to make a change in a tool, it was most certainly not compiling at all, and you had to spend the next half hour to track down what changed since last time, which could be several weeks; change lists pile up quite fast during that time. I decided to fix this and wrote a very naive python script that each time it woke up synced to the perforce depot and build everything and then mailed the result back to me. Yes. That's right. Only to me. Stupid. The rest of the project was spent fixing all the small errors in the various projects every morning I came in. But the project actually went smoother after this, whenever something broke it could be fixed fairly fast since the changes was fresh in our minds and limited to a few change lists.
Fast forward to present day. Today I've added a couple of more tricks to my bag and discovered Cruise Control .NET (CCnet from now on). With automatic unit tests and functional tests that the continuous integration server can run, you can be more confident that your change did not break anything. In order to get continuous integration (CI from now on) to work you need one step builds and tests, have everything you need for a build in source control and a server to run it all on.
The setup
Let's look at some of the things you'll need to get your very own CI server up and running. I'm assuming that you're primarily developing on windows boxes, as I got the feeling that most games developers are. If you're running UNIX, that's fine, you are probably going to have a much easier time since there is make, ant, apache and cruise control help you out. That setup is not that very different from this one, but if you're really on a UNIX box I'm assuming that you already know all this stuff and skip through this section.
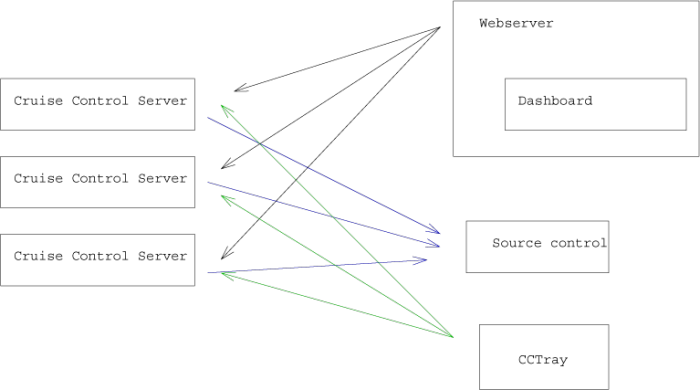
There are five pieces to the puzzle:
- The integration server itself
- The Dashboard
- The CCTray
- The build script
- The source control repository
The integration server itself is just another C# program which can run in either console mode or service mode. It can be setup to poll the source repository and whenever it detects changes it starts a build. It can also send reports through email to people whenever a build finishes with the result.
The dashboard is what keeps it all together, this is a little web applet that runs on an ISS webserver. From the dashboard you can get detailed information about all your projects and their status, their logs and initiate a rebuild of the project. The dashboard can tie into several different integration servers providing a unified view of all projects in the organization.
The CCTray is a little windows tray application that polls the different integrations servers for their status and gives notification whenever they change. Broken builds shows up as ugly red in the tray, with an optional sound playing.
The build script can be anything from a batch file, a nant script or a simple make file. I've found that nant does a good job of gluing other build systems together, right now I'm having CCnet calling a nant script whenever it builds and that in turn calls visual studio on several solutions and various makefiles (for my different python projects). The two fold approach allows me to go through the same motions the server is doing if I want to without moving to the server machine; I simply call nant from the command line on my local machine.
CCnet can integrate with several source control systems, among them CVS, subversion and perforce. Look at the documentation for the full list.
Best practices
Here are some of the best practices I've found with long hours looking at log files, cursing windows and networks in general.
Report broken builds
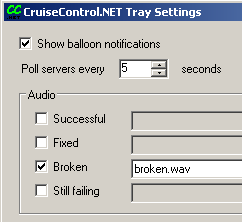
This might seem obvious, what's the point of building if you're not getting a message that the build failed? Well, you'd be surprised. An email just doesn't cut the mustard. Emails can easily be forgotten and they require an email client to be open in order to get them. With the pair programming setup you're usually not at your own desk so to whom should the email go? The CCTray app in the Cruise Control .NET suite is an excellent little application that will pop up a little balloon on the developer's box and play a sound whenever the build breaks. We've got into the practice to having all the computer play this sound whenever the build breaks, it's pretty obvious whenever the build breaks. Have something visual or audible whenever the build breaks in addition to the emails.
Automate
I can not stress this enough. Automation is good. It's what computers are good at, running pre-assembled instructions over and over again. Humans are notoriously bad at this and often forget little steps. 90% automation is just not good enough, only 100% non interactive processes are good. All of your builds and tests should be able to run from a single command, non-interactively and send the result to stdout or an email message. This should be what the CI server runs as well, making it easy whenever you need to debug it to just run it on a local machine. Be sure to automate the whole process as well, build data, code and tools; basically everything that's needed from scratch. If your final product has an installer, make sure that you create this one as well as part of the build step. The goal should be that a new developer coming in with a clean box should only have to sync with the repository and then call the build script and after a cup of coffee a fresh installer should be on their disk.
Have an incremental and a nightly build
Have an incremental build that just builds whatever you need to build for the current change list. The nightly build should be a separate one and this should always be a clean build from scratch using whatever resources are under source control. This will catch some dependency issues where incremental builds that succeeded really failed but since the dependency checking got screwed up it wasn't caught (this happens more often than you would be comfortable with).
Make the incremental build fast
In order to get quick feedback from the build after you've checked in, make sure that the incremental builds are really really fast. If you can get it under a minute, that's great. Cruise Control allows you to easily setup a build farm, to have several computers do different parts of the build. One computer can do a build in debug for win32, another a final build for xbox etc. Got more configurations? Fine, get more build farm computers! Relatively, the fastest most outrageous computer you can buy is still going to be cheaper than having your whole team wait around an extra 2 or 3 minutes for every checking during the day. Team members times # checkins times minutes times average salary == $$$. Also, it's really neat to have a fast build when you do a checkin before lunch, then you don't have to hang around to wait for the servers very long.
Keep checkins small
Keeping the checkins small ensures that one change list is only one thing and if something goes wrong it's easier to find the cause. Huge change lists with multiple changes will easily become monsters that becomes a headache to properly integrate with the main codeline. A small change list is also easy to abandon if you realize that it's not going to work. Fine, do a revert with the source control and start over. Keeping small checkins will also force you to checkin more frequently.
Don't have overlapping checkins
Once you have a notification through CCtray that the build server is building, wait until you have a green light before checking in. Only check in if the build server gives a green light. Having multiple checkins and a red light just increases the search space for the error.
Have Cruise Control in source control
Really. It's a good idea to keep as much as possible in source control anyways, so why not the server itself with executables and configurations? Server disk space is certainly much much more expensive than the disk on your desktop, but given the added benefit that you can have a new server up and running by simply syncing the whole source tree is an appealing one. Upgrades are a breeze, just do it on one and then checkin. The cruise control servers will pick up new configuration files whenever they change, so if you have everything under source control you can actually edit the files on a client box, and then commit them to the repository. The servers will pick up the new configuration when they detect this change when they sync to the repository.
Require minimal per machine configuration
Try to keep the necessary paths and environment variables needed for a build to a minimum. It's pretty easy to inject location specific paths from batch files in windows, see the listing below. This especially becomes important when you need to have two different branches of the repository checked out on the same machine and still have it build. Horror examples like injecting global include and library paths per machine are to be avoided. Having different copies of a repository becomes really common on server machines. Keeping the environment clean is always a good idea since now the server build and the developer build is more likely to be similar (yes, more often they're not for various reasons, checked out files, trash files, different environment etc).
@echo off setlocal set BASEDIR=%~dp0 set SOURCEDIR=%BASE%\..\Shared set PATH=%BASEDIR%;%PATH% pushd %SOURCEDIR% nant popd endlocal
Have the automated build server store good nightly builds
Once the nightly build have been built and all the tests pass, have the server stick this complete package on some storage for quick retrieval. Yes, technically you could sync to that date through your source control system and build if you ever want that build. But this takes time. On a larger source base it can take significant time to just download all the source and data assets. Building them all after that also eats up time. Instead you could just go and unzip/install whatever package you've stored each night. Finding for example when the a bug that wasn't caught by the tests was introduced is now simply a matter of binary search.
Benefits
Once you've started to use continuous integration you will get much faster feedback times from the time you checkin to the time when you discover that it was a breaking change. Before this could take several days, even weeks. Now it should be a matter of minutes. With the changes fresh in mind it's easy to locate what went wrong and fix it. No other changes interfere with yours so it should be pretty easy to track down.
Couple this with automated unit tests and functional tests and the stability of your build should go up. The time spent in broken state should be reduced to a couple of minutes. All in all you will have more confidence in the build and ready to always have something to drop to your customer.
In closing
The hard part in deploying a CI server is not the actual setup, but to infuse the team with the notion that a broken build is a bad thing indeed and whenever that happens, everyone should aiming to fix the problem if needed. Obviously if the problem was that the last guy who checked in forgot to add a new file to the source control program, it's pretty easy. But every now and then integration bugs manifest themselves in very wierd ways that require more people for solving it. Having developers continue to check in stuff while trying to fix the problem in the repository just aggregates the problem, because now we have more points of failure.
Having a continuous integration server should be your very first step in implementing good software engineering practices, even if you are not going down the XP path, CI is still a good idea. I actually use it on my own little project at home. We're two programmers on the team, but we work in different time zones. Checking in and missing some files would stop the other person so build stability is important and also consistency of the repository. It gives me the confidence that everything is under source control that needs to be and that all the little tools project, unit tests and libraries are working (we do have a surprising amount of them given that we're only two people). Taking this to "real" situation in a games studio we could easily have a factor of 10 of tools and libraries that needs to be compiled and tested for every change. Offloading this into an automated process on a server farm keeps the developers develop and the servers testing and building.
Resources