You can know the name of a bird in all the languages of the world, but when you're finished, you'll know absolutely nothing whatever about the bird... So let's look at the bird and see what it's doing -- that's what counts. I learned very early the difference between knowing the name of something and knowing something.
-- Richard Feynman
Introduction
For a couple of years now I've been using a system to manage visual studio projects and solutions automatically. It started out as a massive upgrade operation moving from visual studio 6 to 2002 at the time. In order to do this I decided to also generate all the projects automatically since it was such a pain to maintain them manually. I also didn't trust the settings in the current projects since they were all different from project to project. So I decided to move ahead and write these scripts to handle all the generation for me. Something wonderful happens when you can add files to your project and even projects to your solution with minimal work. It eases the pain to add things in their proper place, instead of just adding functions in some unrelated files (have you stumbled upon filename manipulation routines deep inside your AI?) you can take the trouble now to add the files to the project with proper names. You can also easily add new projects to keep separation into libraries sane.
Are you in single solution hell? Single solution hell is where you have one .sln file for the entire project and all the project files are visible there. You always compile everything, even though you didn't change it. You might even, horror, link in all the projects that show in the solution in your main executable. Consider what this does to your dependencies. No one will notice if you for example in the low level allocator references some higher engine code. You've suddenly tied the core library to the game engine. A very bad thing. Especially if you're sharing the code between tools as well, now you've forced the poor fellow maintaining the Maya plugins to link in the entire engine. All he wanted to do was to export some triangles...
Project layout
Here is some of the philosophy I've acquired through working with Noel at High Moon about the layout and setup of a repository. This directly translates to many of the decisions made in BadgerConfig as well as serves as a guideline on how to manage a large number of libraries and engine code.
First off, try to have minimal amount of non-relative paths. This will pay off when you want to setup new machines or branch. If you never branch, this might be a minor point since you can make a batch script to setup the environment variables for new machines, but branching is a powerful tool when developing larger software projects so for that alone try to keep them low, preferably zero. The ability to work simultaneously on two branches simply by opening two different solutions is quite nice.
If you plan on branching, or consider the possibility, make sure that the local directory structure reflects this. In perforce for example, you can bake this into your repository path. The main trunk I usually just call main for short. Then there can be sibling directories that's the branches. The tree might look something like this:
//foo/company/main/... //foo/company/alpha/... //foo/company/e3/...
Inside the trunk directory there is four major directories, external, shared, tools and projects. Here is what goes inside the different dirs:
- External Stuff that you didn't write, like Lua, zlib etc.
- Shared Libraries used in projects. Stuff like math, core, graphics etc.
- Tools Code that is tool specific. E.g. your Maya code would go in here.
- Projects Here each specific game gets it's own directory with code and assets in them.
Having this setup, let's look inside the Shared directory. We're setting this whole thing up so that we can put an include search path to the shared directory and thus have code in our codebase that includes things by library name and filename. E.g.
#include <Core/New.h> #include <Math/Vector.h> #include <Sound/Clip.h>
One level of name there from the library name allows us to use very short names without any prefix. It also allows duplication if we so chose (even though it could be argued that it's bad). Since I practice some unit testing I like to arrange my libraries to have unit tests in them, basically like this for the library Math:
Math/Build/Win32/Math.vcproj Math/Tests/Build/Win32/TestMath.vcproj Math/Tests/Build/Win32/TestMath.sln
This also ensures that at all times there can not creep in any unknown dependencies to the math library since the test executable suddenly would stop linking. I've seen people trying to get cute here and starting to implement whole libraries in headers to get around icky link dependencies. Please don't wander down that path, there lies madness and worse.
You might notice that I've put all the build related files in a separate directory naming the platform I'm building for. This helps immensely since in any given solution you open you only see the files relating to that particular platform. I've also separated out Win32 and Tool, which might seem strange since usually most of the developers out there write their tools on the the Win32 platform. It's more of a philosophical separation, Win32 denotes some kind of game target where we try to ban stuff like massive use of STL and other perfectly legit code for tools which have a different performance target. I've found it useful in the past, your mileage might vary of course.
The file GenerateSkeleton.py in BadgerConfig actually generates this structure automagically for you as well as stub files for testing.
BadgerConfig basic concept
BadgerConfig, or BC for short, does a very simple thing. It translates a template text file into it's final form through a set of rules. For visual studio projects, the template looks like a stripped .vcproj file with funny tags in them as placeholder for the stuff that we want to generate differently for different projects. A sample might look like this:
<VisualStudioProject
ProjectType="Visual C++"
Version="8.00"
Name="BadgerConfig"
ProjectGUID="%%%UUID%%%"
Keyword="Win32Proj"
>
....
As you might have guessed, the tags enclosed in three percent signs are the ones that BC replaces. It does that through information gathered primarily through two files, the .bdcfg file for the project and the SourceFiles file usually referenced from the .bdcfg file. Writing the template requires you to have intimate knowledge on how the final file looks like, if you write the .vcproj template you need to know that particular format (I usually gain knowledge about the format through a little trial and error, you fire up a blank project and then make the changes you want and then inspect the saved .vcproj file). Writing the .bdgcfg file requires a little knowledge of BadgerConfig, but usually you can just follow the steps with little problems. Let's look at a sample that I actually use:
[General] Type = StaticLibrary SourceFiles = SourceFiles;../SourceFiles [Project] Uuid=7fa9ddc8-dd42-42ef-8059-c00c9efd9a2a Libraries=Ws2_32.lib Includes=../../..
As you can see, the format itself is just a standard .ini file. All the paths are relative to the file itself, which is a common theme in BC (almost all the files work like that). It has two sections so far, a general section where we describe generic stuff as what type of project it is as well as where to find more information. The Project section is actually shorthand for Visual Studio Project section. This is where the .vcproj specific stuff goes, you might imagine another section in the future named Makefile for makefile generation. The UUID needs to be a unique identifier, it can be generated through the command tool uuidgen.exe which comes with visual studio itself. Most of the keys inside the Project header are directly substituted into the template, there are keys for include files, libraries and many other options. By modifying the templates you can easily extend the number of supported keys here yourself. There is in some cases a very small translation that happens before taking the text in the .bdgcfg file and pasting it into the template file, that's all handled by the table fixupRules in GenerateProject.py. It's a simple python dict that maps keywords to a string transform function. Taking a look at the sample ones you should have no trouble writing your own.
The above just generates a project in the end. If we want to add a solution as well, we need to include another section:
[General] Type = ConsoleApplication SourceFiles = SourceFiles;../SourceFiles [Project] Uuid=baa7cb88-8db5-4568-92c0-b645e3333d08 PostBuildCommand=$(TargetPath) -unittest [Solution] Dependencies=Network;Log;Core;AuroraTest DependenciesPaths=../../../../Shared
The Solution section triggers a generation of solutions if you run GenerateSolution.py on it.
The SourceFiles file
As you might have noticed I've totally omitted how we bring in references to source files (.cpp and .h) to the projects. This is done through the SourceFiles directive in the General section. It's a semicolon separated list where you can reference several flat files. The flat files in the most cases are just a list of relative paths (from the SourceFiles itself) to the files you want to appear in the project. An example would be:
../Main.cpp ../TestLogEvent.cpp ../TestLogLevel.cpp ../TestLogSystem.cpp ../TestLogSystemHelp.cpp
As projects becomes more complex, you usually need more control of individual files. To this end there are several extra options you can specify. This is of course extendable, but the options that are supported right now are:
# Support for precompiled headers under MSVC ../Win32/PreCompiled.cpp|PreCompiled=1 ../Win32/PreCompiled.h # Custom rules ../Data/FourColors.bmp|CustomRule=GenerateBinaryInline,.bmp.inl ../Data/16x16_arrow.dds|CustomRule=GenerateBinaryInline,.dds.inl ../Data/16x16_arrow.tga|CustomRule=GenerateBinaryInline,.tga.inl ../Data/Advanced.fx|CustomRule=GenerateBinaryInline,.inl ../Data/PassThrough.fx|CustomRule=GenerateBinaryInline,.inl # Disable language options ../../Foobar.cpp|LanguageExtensions=0
The customrule tag is the most useful one for writing unit tests coupled with the bin2c.py script which can transform any file into a C-style array that you easily can include into your test code to bypass loading testdata from disk.
Typical workflow
Usually you can just keep visual studio up while you add new files to the SourceFiles file. I have a little stub script looking like this in my path:
@echo off setlocal set BASE=%~dp0 %BASE%..\Tools\BadgerConfig\GenerateAll.py %1 endlocal
This allows me to just type "gen" whenever I want to rebuild all the .vcproj files recursively from the current directory. Since the dependency searching for the solution files takes slightly longer, I've keyed it to another command, "gen sln" which regenerates everything.
Generating mega solutions
Having all these little projects might be all well and good for developing small libraries, but what if you want to just compile everything locally? Hopefully you have some kind of build server to do this tedious task but in case you want to have a one solution fits them all, there is a facility inside GenerateSolution.py that collects all the subsolutions and generates one big one. This is very useful as a sanity check when you've done several changes locally and want to find out if you've introduced some unwitting link dependency or such before checking in. The dependency check inside visual studio is surprisingly fast for this so having a solution with 40 projects (as I have here at home) is very very fast. For iteration a single hit on build with nothing to do takes about half a second on my machine.
========== Build: 0 succeeded, 0 failed, 40 up-to-date, 0 skipped ========== Total build time: 00:00:00.26
You can generate mega solutions by issuing "GenerateSolution.py <solutionname> <platformname>".
Coping with redundancy
Most, if not all, the projects in the the shared folder will have the exact same settings for things like include paths, libraries linked against etc. You can pull all these common settings into a mast config file (it's called MasterConfig inside the templates directory). This is a .bdgcfg type file, where you can specify the defaults for the platform. This can be used for example to reference specific versions of lua etc. It makes upgrading versions of external libraries a breeze.
The distribution
Looking at the files in the zip file, there are a number of python files. Let's go though them.
FileItem.py Engine.py PathHelp.py
They are all internal files to BC. You should not need to run them.
ListSourceFiles.py
This little script can help you generate SourceFiles when you do migration from a current project that uses visual studio.
GenerateSkeleton.py
This script setups a new environment for a small shared library.
GenerateProject.py
This script generates a .vcproj file from a given .bdgcfg file.
GenerateSolution.py
This script generates a .sln file from a given .bdgcfg file.
Templates/Win32/MasterConfig
This is the masterconfig for the win32 platform. Can be changed at will (you've gotten my test one and all the paths and defines will be off).
Templates/Win32/CppBuildTemplate.vcproj
This is the template for the win32 platform. You should read it and see how it works (it will give clues as to what the keywords do).
GenerateAll.py
This is the main entry point, this does a recursive search for all the .bdcfg files and regenerates everything.
Improvements
The integration with visual studio can be made much better. At High Moon we had a small plugin that detected added files and automatically added them to the SourceFiles file.
The documentation for this project is basically this article and the source code. It's probably not going to change.
More build backends should be added, Makefiles and/or nant.
In closing
I've described a system that can help you cope with numerous projects and sweeping changes to those projects with ease. There are of course several systems like this out there already, notably cmake, premake and omake. All of these systems are much more capable that BadgerConfig. They are also a lot more complex and the reason why I wrote this to begin with was that I'm sick and tired of these one hammer fits them all solutions. BadgerConfig uses another build system, any buildsystem in fact, to actually build the source. It's easy to retarget BC to either Makefiles or Nant.
Now, that said, before you jump and convert the whole company's projects to this, understand that this system is not by near complete in any sense. You will need a person who is proficient with python and can read my somewhat hacky code here to make any changes. In my experience there will always be cries for changes. While working on the smartconfig system at High Moon we made changes to that system rather frequently actually. In the end it was rather mature, but also rather hacky. It was the only system we had that wasn't unit tested and it was a stark contrast.
Still, if you are maintaining manual .vcproj files, consider to stop doing that and switch to an automated system that generates the files for you. The added benefit that you can change all the compiler settings, linker settings etc consistently for all the projects can not be underestimated. Experiments like "what would compile for size do to the speed of our project?" takes a matter of seconds instead of going through all the projects for hand and changing the settings.
Ok. Enough. Here is the zip file. Enjoy!
Update Oct 14, 2007.
I've gotten some questions about how it all works and here is hopefully some helpful examples to clarify how it's supposed to work.
It's important to realize that all the paths given in any config file relating to badger config is supposed to be a path relative to that particular config file. So say for example that we have the following setup:
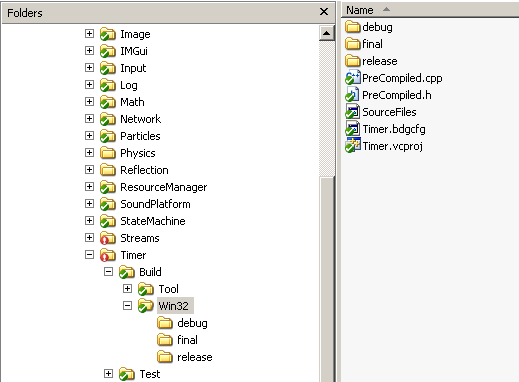
As you can see we have a "SourceFiles" file in the Build/Win32 directory. This needs to look something like this:
../../Timer.h ../../Timer.cpp ../../TimeSource.h ../../TimeSource.cpp
Here we reference the actual cpp and headers in the parent directory. Internally the paths are converted to absolute paths everywhere and then converted back to relative paths, but relative to the final output file (in this case the .vcproj file) so that the final product can be checked into source control and then used on another computer seamlessly.
Worthy of note is also that you will need one .bdgcfg file per .vcproj file you want to produce, and the .vcproj file will be created in the same directory as the .bdgcfg file. This directory needs to be in the structure I described before with the parent directory named for the platform. E.g. <projectname>/Build/Win32/<projectname>.bdgcfg would be a good name.
The files from the distribution, please unzip them somewhere convenient on your harddrive, e.g. c:/usr/local/badger and then create some cmd script like in listing (6) to reference the GenerateAll.py file and place that command script in your path somewhere so that you can easily access things. Don't forget to also edit the templates in the Templates/Win32 directory.
The UUID key in the badgerconfig file is very important, it needs to be unique for each project. I recommend for now that you use the uuidgen.exe program to generate the string, in the future I'll see if I can incorporate a scheme to automatically generate a stable hash from the projectname and use that instead (thanks Nick for the idea!).